Tokens dans les LLM : guide complet pour comprendre l'IA moderne
Découvrez ce que sont les tokens dans les modèles de langage (LLM), pourquoi ils sont essentiels et comment ils influencent les performances de l'IA. Guide accessible pour tous
Les fondamentaux des LLM : comprendre les tokens, ces briques essentielles de l’intelligence artificielle
Avez-vous déjà été fasciné par la capacité des intelligences artificielles comme ChatGPT à comprendre vos questions et y répondre de façon pertinente ? Derrière cette apparente magie se cache un mécanisme fondamental : le traitement par tokens. Mais qu’est-ce qu’un token exactement, et pourquoi est-il si crucial dans le fonctionnement des modèles de langage avancés ? Plongeons ensemble dans cet élément essentiel qui façonne notre interaction quotidienne avec l’IA.
Qu’est-ce qu’un token dans un modèle de langage ?
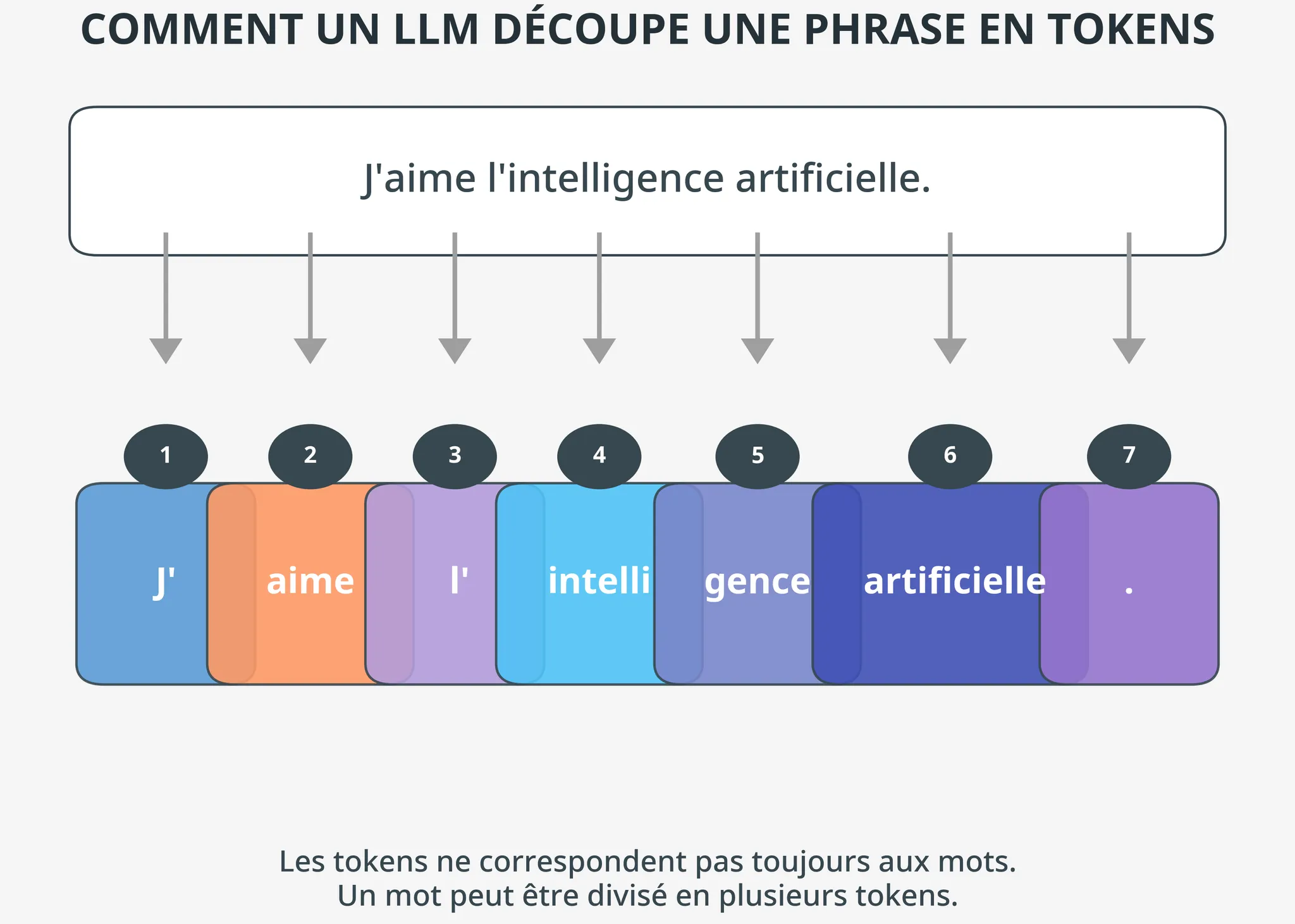
Un token est la plus petite unité de texte qu’un modèle de langage (LLM) peut traiter. Contrairement à ce que l’on pourrait penser intuitivement, un token ne correspond pas nécessairement à un mot entier ou une syllabe. Il peut s’agir d’un mot, d’une partie de mot, d’un caractère spécial ou même d’un espace.
Pour mieux comprendre, imaginez que vous découpez un texte en petits morceaux pour le faire passer dans une machine. Ces morceaux doivent être suffisamment petits pour être traités efficacement, mais suffisamment significatifs pour conserver du sens. C’est exactement ce que font les LLM avec les tokens.
Prenons un exemple concret : la phrase “J’aime l’intelligence artificielle” pourrait être divisée en tokens comme ceci : [“J’”, “aime”, ” l’”, “intelli”, “gence”, ” artificielle”]. Remarquez comment certains tokens incluent des espaces, tandis que d’autres représentent des fragments de mots ou des signes de ponctuation.
Comment fonctionne la tokenisation ?
La tokenisation est le processus qui transforme un texte brut en une séquence de tokens. Cette étape est cruciale car elle constitue la première transformation que subit un texte avant d’être traité par un LLM.
Les algorithmes de tokenisation suivent généralement ces principes :
Pour les langues occidentales, les tokens sont souvent des sous-mots, ce qui permet de gérer efficacement les mots rares ou inconnus en les décomposant en parties plus familières. Par exemple, le mot “antidéconstitutionnellement” pourrait être divisé en plusieurs tokens comme [“anti”, “dé”, “constitution”, “nelle”, “ment”].
Pour les langues comme le chinois ou le japonais, qui n’utilisent pas d’espaces entre les mots, la tokenisation s’appuie sur d’autres méthodes pour identifier les unités significatives.
Les modèles comme GPT utilisent des tokeniseurs sophistiqués qui ont été entraînés sur d’immenses corpus de textes pour déterminer les divisions les plus efficaces. Ces tokeniseurs cherchent à optimiser la représentation du langage en équilibrant la taille du vocabulaire (nombre total de tokens possibles) et la longueur moyenne des séquences produites.
Pourquoi les tokens sont-ils si importants ?
Les tokens jouent un rôle fondamental dans les LLM pour plusieurs raisons :
1. Ils déterminent la capacité de traitement
Chaque modèle a une limite de tokens qu’il peut traiter simultanément. Par exemple, GPT-3.5 peut gérer environ 4 096 tokens à la fois, tandis que GPT-4 peut en traiter jusqu’à 8 192 ou plus selon les versions. Cette limite définit la “fenêtre de contexte” du modèle, c’est-à-dire la quantité d’information qu’il peut considérer pour générer une réponse.
Lorsque vous interagissez avec un LLM, chaque message que vous envoyez et chaque réponse que vous recevez consomment des tokens. Si votre conversation devient trop longue, le modèle commencera à “oublier” les premiers échanges car ils sortent de sa fenêtre de contexte.
2. Ils influencent les coûts d’utilisation
La plupart des API de LLM facturent en fonction du nombre de tokens traités. Plus votre requête est longue, plus elle coûte cher. C’est pourquoi les développeurs cherchent souvent à optimiser leurs prompts pour obtenir les meilleurs résultats avec le moins de tokens possible.
3. Ils affectent la qualité des réponses
La façon dont un texte est tokenisé peut influencer la compréhension du modèle. Certains mots techniques, noms propres ou termes spécialisés peuvent être mal tokenisés, ce qui peut affecter la qualité des réponses. C’est particulièrement vrai pour les langues moins représentées dans les données d’entraînement.
Les particularités de la tokenisation selon les langues
La tokenisation ne fonctionne pas de manière identique dans toutes les langues. Voici quelques différences notables :
En anglais, un token représente en moyenne environ 4 caractères ou 3/4 d’un mot.
En français, les tokens sont généralement plus longs en raison de la structure de la langue et de ses particularités grammaticales.
Dans les langues asiatiques comme le japonais ou le chinois, un seul caractère peut représenter un concept entier, ce qui rend la tokenisation très différente.
Ces différences expliquent pourquoi traduire un texte peut changer significativement son nombre de tokens. Par exemple, un texte de 100 tokens en anglais pourrait nécessiter 130 tokens ou plus une fois traduit en français.
Comment optimiser l’utilisation des tokens ?
Pour tirer le meilleur parti des LLM tout en maîtrisant les coûts et les limitations, voici quelques conseils pratiques :
-
Soyez concis dans vos requêtes : Éliminez les informations non essentielles et allez droit au but.
-
Utilisez des formats structurés : Les instructions claires et bien organisées permettent souvent d’obtenir de meilleures réponses avec moins de tokens.
-
Comprenez les limites de votre modèle : Savoir combien de tokens votre modèle peut traiter vous aidera à structurer vos interactions de manière plus efficace.
-
Testez différentes formulations : Parfois, reformuler une question peut réduire significativement le nombre de tokens nécessaires tout en améliorant la qualité de la réponse.
Les tokens et l’avenir des LLM
À mesure que les modèles de langage évoluent, leur capacité à traiter des contextes plus longs augmente. Les dernières versions de modèles comme Claude ou GPT-4 peuvent désormais gérer des dizaines voir des centaines de milliers de tokens, permettant des analyses de documents entiers ou des conversations beaucoup plus longues.
Cette évolution ouvre de nouvelles possibilités, comme l’analyse de contrats juridiques complexes, la génération de résumés détaillés de livres entiers, ou encore des assistants IA capables de maintenir une mémoire conversationnelle sur de longues périodes.
Cependant, même avec ces avancées, comprendre et optimiser l’utilisation des tokens reste essentiel pour quiconque souhaite exploiter pleinement le potentiel des LLM.
Conclusion : les tokens, bien plus qu’un détail technique
Les tokens sont bien plus qu’un simple détail technique dans le fonctionnement des LLM. Ils représentent la façon dont ces systèmes perçoivent et traitent le langage humain. En comprenant comment fonctionne la tokenisation, vous pouvez non seulement utiliser ces outils plus efficacement, mais aussi mieux appréhender leurs forces et leurs limites.
Que vous soyez un utilisateur occasionnel de ChatGPT ou un développeur intégrant des LLM dans vos applications, cette connaissance vous permettra d’obtenir de meilleurs résultats et d’anticiper les évolutions futures de cette technologie fascinante.
La prochaine fois que vous interagirez avec un LLM, rappelez-vous que derrière chaque mot de sa réponse se cache ce processus fondamental de tokenisation, véritable pont entre notre langage humain et l’intelligence artificielle.