Les Embeddings expliqués : Comment les vecteurs alimentent l'intelligence des LLM ?
Découvrez comment les embeddings (vecteurs de représentation) transforment le texte en données mathématiques et permettent aux LLM de comprendre le langage humain. Guide complet et accessible.
Les Embeddings : La magie invisible derrière les LLM
Avez-vous déjà été impressionné par la capacité d’un chatbot à comprendre vos questions, même formulées différemment ? Ou peut-être vous êtes-vous demandé comment Google parvient à trouver des résultats pertinents, même lorsque vous n’utilisez pas exactement les mêmes mots que dans les pages web ? Derrière ces prouesses se cache une technologie fascinante : les embeddings, ou vecteurs de représentation.
Qu’est-ce qu’un embedding, exactement ?
Imaginez que vous deviez expliquer à un ordinateur ce qu’est une “pomme”. Comment procéderiez-vous ? Les ordinateurs ne comprennent pas naturellement les mots comme nous. Pour eux, tout doit être traduit en nombres.
Un embedding est précisément cela : une traduction de mots, phrases ou documents en séries de nombres (vecteurs) qui capturent leur signification. C’est comme si chaque mot ou concept recevait ses propres coordonnées dans un espace mathématique multidimensionnel.
“Les embeddings sont la colonne vertébrale sémantique des LLM, la porte par laquelle le texte brut est transformé en vecteurs de nombres compréhensibles par le modèle”, explique un expert de Hugging Face. Cette transformation est fondamentale pour permettre aux machines de comprendre les nuances du langage humain.
Pourquoi les embeddings sont-ils si importants ?
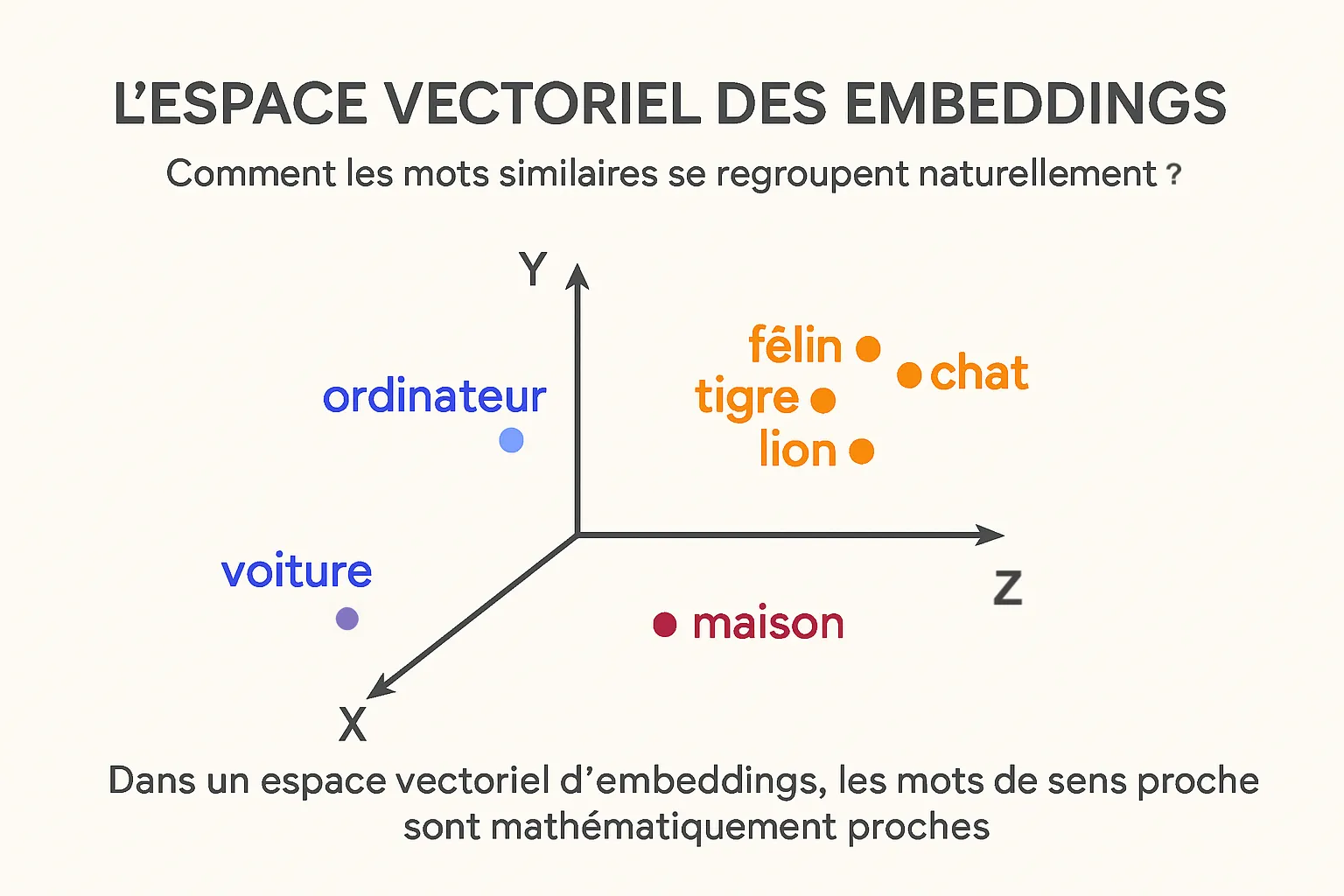
Pour comprendre l’importance des embeddings, prenons une analogie simple. Imaginez une bibliothèque où, au lieu de ranger les livres par ordre alphabétique, vous les placeriez par similarité de contenu. Les romans policiers seraient proches les uns des autres, tout comme les livres de cuisine ou les ouvrages scientifiques.
C’est exactement ce que font les embeddings dans l’espace vectoriel : ils positionnent les mots ou concepts similaires à proximité les uns des autres. Ainsi, “chat” et “félin” seront proches, tandis que “chat” et “voiture” seront éloignés.
Cette organisation spatiale permet aux modèles d’intelligence artificielle de :
- Comprendre les relations sémantiques entre les mots
- Saisir les nuances et le contexte d’une phrase
- Faire des associations pertinentes entre différents concepts
- Générer des réponses cohérentes et contextuelles
Comment fonctionnent les embeddings ?
Lorsque vous saisissez une phrase dans un modèle de langage comme ChatGPT, chaque mot est d’abord transformé en un vecteur d’embedding. Ce n’est pas une simple substitution mot-à-nombre, mais plutôt une représentation complexe qui capture le sens du mot dans différents contextes.
Ces vecteurs possèdent généralement des centaines ou des milliers de dimensions. Chaque dimension peut être vue comme une caractéristique particulière du mot : son niveau de formalité, son champ lexical, sa connotation émotionnelle, etc.
Par exemple, le mot “banque” pourrait avoir des valeurs élevées dans les dimensions liées à la finance, aux institutions, aux services, mais des valeurs faibles dans les dimensions liées à la nature ou à la cuisine.
Ce qui est fascinant, c’est que ces représentations ne sont pas créées manuellement par des humains. Elles émergent naturellement lorsqu’un modèle est entraîné sur d’énormes quantités de textes. Le modèle apprend progressivement quels mots apparaissent dans des contextes similaires et ajuste leurs vecteurs en conséquence.
L’évolution des embeddings : de simples à sophistiqués
Les techniques d’embeddings ont considérablement évolué au fil du temps :
Les débuts : One-Hot Encoding
À l’origine, les mots étaient représentés par des vecteurs “one-hot” : un vecteur rempli de zéros, avec un seul “1” à la position correspondant au mot dans le vocabulaire. Simple mais inefficace, cette méthode ne capturait aucune relation entre les mots.
La révolution Word2Vec
En 2013, Google a introduit Word2Vec, une technique révolutionnaire qui a permis de créer des embeddings capturant véritablement les relations sémantiques entre les mots. Soudain, les modèles pouvaient comprendre que “roi” est à “homme” ce que “reine” est à “femme”.
Les embeddings contextuels
Les techniques modernes comme BERT et GPT ont introduit les embeddings contextuels. Contrairement aux modèles précédents où un mot avait toujours le même vecteur, ces modèles génèrent des embeddings différents selon le contexte. Ainsi, “avocat” aura un embedding différent dans “J’ai mangé un avocat” et “J’ai consulté un avocat”.
Les embeddings dans les LLM : le cœur du système
Les Grands Modèles de Langage (LLM) comme GPT-4 ou Claude reposent fondamentalement sur les embeddings. Ils constituent la première étape du traitement de toute information textuelle.
“Quand vous interrogez un LLM pour vous aider à déboguer votre code, vos mots et tokens sont transformés en un espace vectoriel de haute dimension où les relations sémantiques deviennent des relations mathématiques”, explique un chercheur en IA.
Cette transformation permet aux LLM de :
- Comprendre votre requête en la situant dans l’espace vectoriel des concepts qu’ils connaissent
- Identifier les informations pertinentes en recherchant des vecteurs similaires dans leur base de connaissances
- Générer des réponses cohérentes en produisant des séquences de tokens dont les embeddings s’enchaînent logiquement
Applications pratiques des embeddings
Les embeddings ne sont pas qu’un concept théorique. Ils sont au cœur de nombreuses applications que nous utilisons quotidiennement :
Recherche sémantique
Lorsque vous effectuez une recherche sur Google ou dans une base de données moderne, les embeddings permettent de trouver des résultats pertinents même si vous n’utilisez pas exactement les mêmes mots que dans les documents recherchés.
Recommandations personnalisées
Les systèmes de recommandation de Netflix, Spotify ou Amazon utilisent des embeddings pour représenter vos préférences et vous suggérer des contenus similaires à ceux que vous appréciez déjà.
Analyse de sentiment
En transformant les textes en embeddings, les entreprises peuvent analyser automatiquement le ton et le sentiment exprimés dans les avis clients ou les mentions sur les réseaux sociaux.
Traduction automatique
Les systèmes de traduction modernes utilisent des embeddings pour capturer le sens des phrases dans une langue source avant de les traduire dans une langue cible.
Au-delà du texte : des embeddings pour tout
Bien que nous ayons principalement parlé d’embeddings textuels, cette technique s’étend à d’autres types de données :
Embeddings d’images
Les réseaux de neurones peuvent transformer des images en vecteurs d’embeddings, permettant de rechercher des images similaires ou de comprendre leur contenu.
Embeddings audio
La musique, la parole et autres signaux sonores peuvent également être convertis en embeddings, facilitant la reconnaissance vocale ou la recherche de morceaux similaires.
Embeddings de graphes
Les réseaux sociaux ou autres structures relationnelles peuvent être représentés par des embeddings de graphes, permettant d’analyser les communautés ou de prédire de nouvelles connexions.
Les défis et limites des embeddings
Malgré leur puissance, les embeddings présentent certaines limitations :
Biais incorporés
Les embeddings sont créés à partir de textes existants, qui contiennent souvent des biais sociétaux. Ces biais se retrouvent alors encodés dans les vecteurs, pouvant mener à des résultats problématiques.
Perte de nuances culturelles
Les subtilités culturelles, l’humour ou les références locales peuvent être mal représentés dans les espaces vectoriels, surtout lorsque les données d’entraînement sont limitées à certaines cultures ou langues.
Coût computationnel
Générer et manipuler des embeddings de haute qualité nécessite d’importantes ressources de calcul, ce qui peut limiter leur utilisation dans certains contextes.
L’avenir des embeddings
L’évolution des embeddings continue à un rythme soutenu. Les recherches actuelles explorent plusieurs pistes prometteuses :
Embeddings multimodaux
Ces techniques visent à créer des représentations unifiées pour différents types de données (texte, image, son), permettant une compréhension plus holistique du contenu.
Embeddings personnalisés
Des embeddings adaptés à des domaines spécifiques (médical, juridique, technique) permettent d’améliorer les performances des modèles dans ces contextes particuliers.
Embeddings plus efficaces
Des recherches visent à réduire la taille des vecteurs d’embeddings tout en préservant leur richesse sémantique, rendant leur utilisation plus accessible.
Conclusion
Les embeddings sont véritablement la magie invisible qui permet aux modèles d’IA de comprendre notre langage. En transformant les mots en vecteurs mathématiques, ils créent un pont entre notre monde conceptuel humain et l’univers numérique des machines.
À mesure que cette technologie continue d’évoluer, nous pouvons nous attendre à des interactions toujours plus naturelles et nuancées avec nos assistants IA. Les embeddings, bien que cachés derrière l’interface utilisateur, constituent la fondation sur laquelle repose toute la compréhension du langage par les machines.
La prochaine fois que vous serez impressionné par la pertinence d’une réponse d’un chatbot ou par la précision d’une recherche, rappelez-vous qu’au cœur de cette prouesse se trouvent ces fascinants vecteurs de représentation, traduisant silencieusement notre langage en un format que les machines peuvent comprendre et manipuler.